
🎯 Ce guide a pour objectif de vous aider à obtenir et analyser les indicateurs essentiels d’un serveur Linux.
Il se concentre sur les composants matériels du système et fournit les clés nécessaires pour analyser les performances de votre machine.
Les notions présentées ici vous permettront d’identifier rapidement les signaux faibles, de comprendre les comportements d’un serveur sous charge
et d’interpréter correctement les métriques CPU, mémoire et disque. Elles s’appuient sur les outils standards disponibles sur toutes les distributions Linux.
Ce document constitue un socle commun pour faciliter les échanges techniques entre vos équipes et le support Free PRO XPR
Quelques notions essentielles ⌨️ #
Avant d’entrer dans les commandes, quelques concepts sont utiles :
- CPU : capacité de traitement du serveur.
- Processus / tâches : programmes en cours d’exécution.
- Load average : nombre moyen de tâches en cours ou en attente.
- Mémoire (RAM) : espace de travail des applications.
- Cache : mémoire utilisée par Linux pour accélérer les accès disque.
- Swap : extension lente de la RAM sur disque.
- IO / IOPS : opérations de lecture/écriture sur disque.
ℹ️ Lire un indicateur système
Un seul indicateur ne suffit jamais à poser un diagnostic. CPU, load, mémoire et IO doivent être interprétés ensemble pour comprendre la situation réelle.
Supervision de l’utilisation CPU 🔎 #
La commande top permet d’observer en temps réel l’activité CPU et les processus les plus consommateurs.
Informations clés affichées par top
- Uptime : durée depuis le dernier redémarrage.
- Load Average : charge système sur 1, 5 et 15 minutes.
- Users : utilisateurs connectés.
- Tasks : nombre de tâches et leur état.
- CPU(s) : répartition du temps CPU :
- %us : temps utilisateur
- %sy : temps noyau
- %ni : priorité modifiée
- %id : inactivité
- %wa : attente IO
- %hi / %si : interruptions
- %st : steal time (VM)
- Mem / Swap : utilisation mémoire et swap.
Exemples :
top - 10:45:15 up 17 days, 2 users, load average: 2.06, 2.54, 1.19 Tasks: 160 total, 1 running, 159 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.2 us, 0.4 sy, 0.3 ni, 98.3 id, 0.8 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem : 2450.0 total, 1250.0 used, 1200.0 free, 100.0 buff/cache MiB Swap: 4096.0 total, 250.0 used, 3846.0 free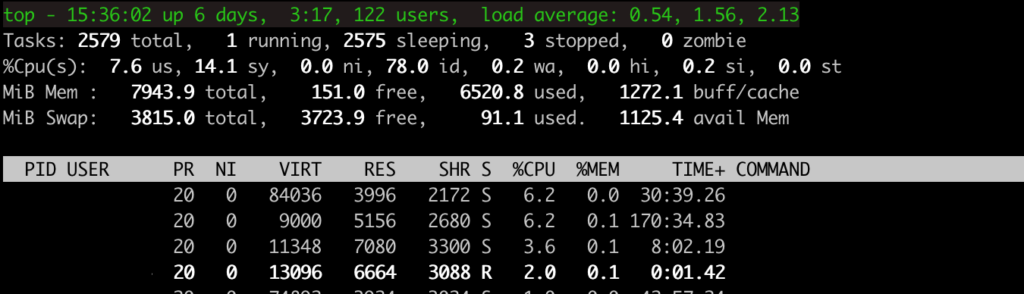
Plus moderne la commande htop offre une vue graphique des informations.

💡Nous vous recommandons de lancer votre commande avec l’argument -d 10 (Rafraichissement des valeurs toutes les 10 secondes)
ℹ️ Quand un CPU élevé est normal — et quand il ne l’est pas
Un CPU élevé est normal lors d’un traitement intensif (compression, calcul, import massif).
Il devient problématique lorsqu’il reste élevé sans activité légitime identifiée.
Supervision de la mémoire 🧠 #
La commande recommandée est :
free -h
Exemple
total used free shared buff/cache available
Mem: 7.8Gi 6.4Gi 191Mi 7.0Mi 1.2Gi 1.1Gi
Swap: 3.7Gi 100Mi 3.6Gi
Points importants
- Linux utilise la RAM libre pour le cache disque → ce n’est pas un problème.
- Le champ available est le plus pertinent pour évaluer la marge réelle.
- La swap utilisée n’est pas un problème tant que le système ne swap pas activement.
💡 Pour une analyse détaillée :
cat /proc/meminfoℹ️ Pourquoi Linux utilise toute la RAM ?
Linux optimise les performances en utilisant la mémoire libre comme cache.
Une RAM “pleine” n’est pas un signe de saturation : seule la mémoire available compte.
Comprendre et superviser la charge (Load Average) 🏋️♀️ #
Le load average représente le nombre moyen de tâches en cours d’exécution ou en attente d’un accès CPU/IO.
Exemple
load average: 1.27, 0.92, 0.73Interprétation
- 1ère valeur : charge sur 1 minute
- 2e valeur : charge sur 5 minutes
- 3e valeur : charge sur 15 minutes
Règle générale
Un système est considéré comme chargé lorsque :
load average ≥ nombre de cœurs CPU
ℹ️ Load élevé ≠ CPU saturé
Un load élevé peut provenir d’attentes disque (IO), d’un manque de mémoire ou d’une contention hyperviseur.
Toujours vérifier %id, %wa et %st.
Comprendre la charge selon les cas #
Charge < 1 (sur un système monocœur)
Indique une machine sous-utilisée.
Action possible : augmenter le débit des requêtes ou paralléliser davantage.
Charge ≈ 1
Le CPU est pleinement utilisé mais non saturé.
Action possible : vérifier si un processus unique monopolise le CPU.
Charge > 1
Ne signifie pas forcément saturation CPU.
Cas typiques
- CPU idle élevé + load élevé → contention IO
- CPU idle ≈ 0 + load élevé → CPU saturé
- %wa élevé → attente disque
- %st élevé → contention hyperviseur (VM)
Action possible : analyser CPU, IO, mémoire et virtualisation.
Supervision des IO #
Les performances disque se mesurent en IOPS (Input/Output Operations Per Second).
Outils utiles
iostat -x 1: statistiques détaillées par disquepidstat -d 1: IO par processusiotop -oPa: IO en temps réeldstat: vue synthétique CPU/mémoire/IObpftrace/bcc-tools: analyse avancéeioping: latence disque
Exemple iostat -x
Device r/s w/s rMB/s wMB/s await svctm util
nvme0n1 12000 8000 450 320 0.2 0.1 98%
Performances typiques
- HDD SATA : ~120 IOPS
- HDD SAS : ~180 IOPS
- SSD SATA : 10 000 – 30 000 IOPS
- NVMe PCIe Gen4/Gen5 : 200 000 – 1 000 000 IOPS
- Baies SAN : dépend du nombre de disques + cache + contrôleurs
ℹ️ Reconnaître une saturation disque en 3 indicateurs
1. await élevé → latence importante
2. util proche de 100 % → disque saturé
3. %wa élevé → CPU en attente d’IO
Synthèse opérationnelle #
Pour lire rapidement l’état d’un serveur :
- CPU : vérifier %id, %sy, %wa, %st.
- Load : comparer au nombre de cœurs.
- Mémoire : se baser sur available, pas sur free.
- IO : analyser await, util, latence.
- Virtualisation : surveiller %st.
Ces éléments permettent d’identifier rapidement la source d’un ralentissement et d’orienter efficacement l’analyse.
Diagnostic rapide d’un serveur Linux #
Lorsqu’un serveur semble lent, une lecture rapide des indicateurs permet souvent d’identifier l’origine du problème.

ℹ️ Bonne pratique
Toujours analyser plusieurs indicateurs simultanément. Un CPU élevé, par exemple, peut être causé par un manque de mémoire ou une saturation disque.
Lorsqu’un serveur semble lent ou instable, quelques commandes permettent d’obtenir un premier diagnostic en moins d’une minute.
htop
free -h
iostat -x 1
Lecture rapide des indicateurs
| Indicateur | Interprétation |
|---|---|
| load average > nombre de CPU | Surcharge potentielle du système |
| %id proche de 0 | CPU fortement sollicité ou saturé |
| %wa élevé | Le CPU attend des opérations disque (IO) |
| available faible | Pression mémoire possible |
| await élevé | Latence disque importante |
ℹ️ Méthode simple
Dans la majorité des cas, l’analyse combinée du CPU, de la mémoire et des IO permet d’identifier rapidement l’origine d’un ralentissement système.